Bitcoin is one of the assets that has increased most in value over the past decade, and it potentially opens a new investable asset class of cryptocurrencies.1 Financial service providers, such as banks and insurers, increasingly leverage bitcoin’s underlying blockchain technology.2 This article explores how the insurance industry could reap the benefits of using blockchain in insurance.
Blockchain Technology Is Compatible With the Insurance Business Model
Similar to insurers building a pool of policyholders to share risks, the blockchain is a network of participants who share information and exchange values on the chain. Mutual insurance, in particular, shares blockchain’s characteristics of being decentralized and autonomous, as policyholders not only own the mutual insurer but also ideally manage and operate it. The modern technology of blockchain realizes a similar vision with smart contracts and immutable records on blocks. In my experience, the operational burden of an insurer can be largely reduced and automated by a carefully designed blockchain network.
The Current Marketplace of Blockchain Applications in Insurance
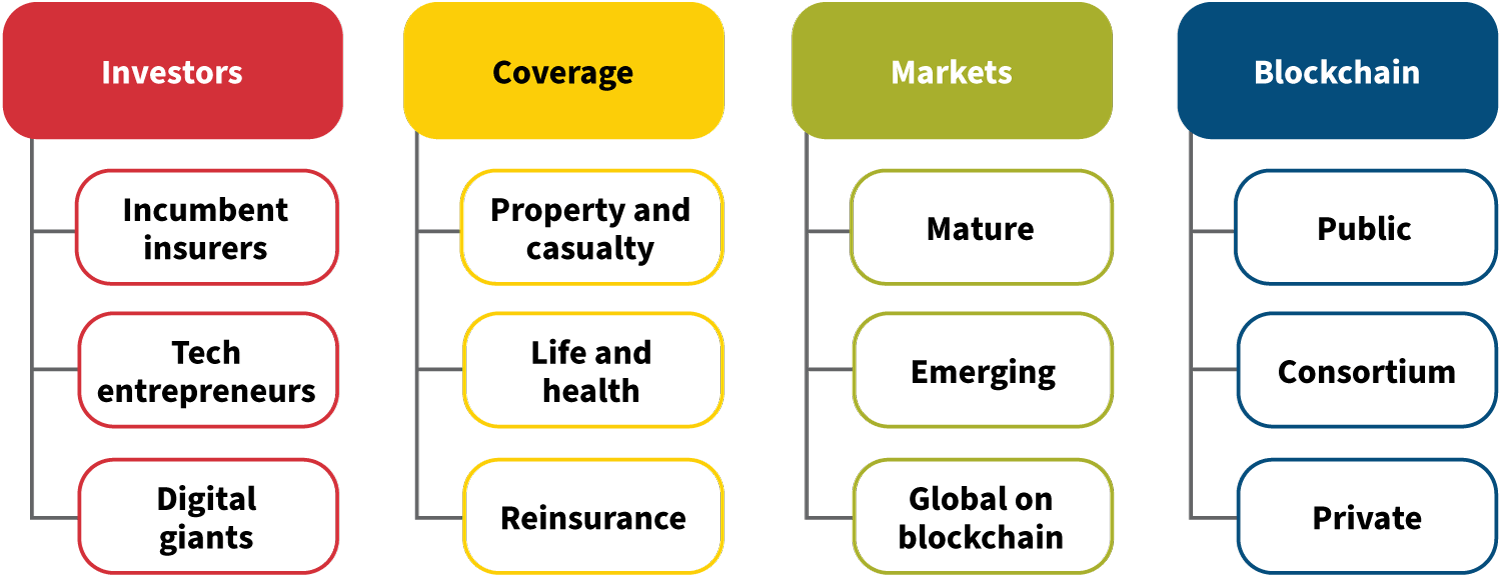
The major players in blockchain insurance are incumbent insurers, tech entrepreneurs and digital giants. In terms of coverage, blockchain insurance encompasses property and casualty (P&C) insurance, life and health insurance, and reinsurance. Its development has occurred in both mature and emerging markets, with certain applications specifically targeting the global blockchain market. In terms of the blockchain technology itself, blockchain insurance has been built on public, consortium and private blockchains. Each has its own benefits and disadvantages.
Figure 1: Overview of Blockchain Applications in Insurance
Potential Benefits of Blockchain Applications in Insurance
Smart-contract-enabled automatic execution has the potential to improve certainty, trust and efficiency in insurance (e.g., claims management) and reduce fraud in insurance transactions.3 More generally, blockchain technology can reduce administrative costs and streamline insurance processes by eliminating the need for intermediaries. The improved efficiency and reduced operational costs may, in turn, increase the accessibility, affordability and availability of insurance. Similar to how blockchain (bitcoin) enables transactions between the unbanked, it can offer coverage to the world’s uninsured population, making insurance more inclusive. Therefore, blockchain technology has the potential to improve the efficiency of traditional insurance, enable new business models and open new opportunities in inclusive insurance.
The potential benefits of blockchain in insurance are still in the development stage, as achieving profitability and scalability in blockchain projects continues to pose challenges. The Geneva Association’s empirical findings reveal that blockchain-based insurance solutions are primarily found in large, competitive markets and are confined to specific nonlife sectors like crypto-related risks. Despite anticipation, efficiency enhancements and novel business prospects have yet to materialize. As supported by The Geneva Association’s findings, blockchain insurance initiatives have not yet spurred substantial growth in the insurance sector or notably advanced financial inclusion.4
Use of Blockchain in Insurance
Three blockchain use cases in insurance illustrate common successes and lessons learned.
- Nexus Mutual is a members-owned leader in public, blockchain-based DeFi insurance, offering an alternative approach to insurance by addressing risks associated with crypto assets and protocols. In my view, the case of Nexus Mutual presents a mixed outlook. On one hand, its business model achieves semi-decentralization, providing more than 8,000 insurance coverages for crypto-related risks and processing more than 150 claims while maintaining solvency and consistently attracting capital investment. On the other hand, as the case study reveals and I understand it, Nexus Mutual remains relatively small in scale compared to traditional insurance operations—likely due to challenges related to distribution, diversifying into off-blockchain lines of business and repercussions from significant cryptocurrency failures.5
- B3i, a blockchain insurance industry initiative, aimed to tackle challenges in the reinsurance sector such as information sharing, communication, accounting and claims management. However, it faced insolvency in 2022 when it couldn’t secure new capital of US$20 million. The B3i experience indicates that insurers and reinsurers may not be prepared for widespread adoption of blockchain-based transactions. B3i pursued multiple objectives and implemented a complex consortium governance framework, which may have contributed to its failure. This case study indicates that to realize the expected efficiency gains and business growth, all participating parties may need to be in the blockchain ecosystem, which may take much longer than anticipated.
- AnnChain (ZQAlink) originated from ZhongAn Insurance, China’s first online insurance company, and serves as a prime illustration of how to leverage blockchain technology to explore new insurance prospects.6 Specifically, it recognizes the need for credit insurance within a blockchain-powered supply chain finance framework. Though its ambition is to achieve substantial growth in the near future, the company remains uncertain whether this blockchain-driven credit insurance model can be extended to other areas of business.
In taking a comprehensive view of the blockchain initiatives InsurTechs, major technology firms and incumbent insurers are pursuing, it appeared to me that there are common characteristics that contribute to their success. They are establishing feasible objectives, steering clear of mission creep, implementing robust governance structures and targeting precise pain points within current business practices. Typical hurdles involved scalability and achieving short-term profitability. Blockchain projects may falter without rapid returns on investments, which are crucial for sustaining ongoing investment influx.
Further insights suggest that consortium blockchains may not offer substantial advantages over current technologies for established insurance firms. Public blockchains, with benefits that include a neutrally credible settlement layer, transparency and interoperability, could present a more promising avenue, in my opinion. Additionally, I believe blockchain insurance initiatives could prioritize addressing specific problems rather than solely focusing on the technology itself. I believe future blockchain insurance solutions aimed at new business opportunities should lower knowledge barriers, such as digital literacy, to realize the intended benefits of transparency and achieving economies of scale.
Short- and Long-Term Trends
As American scientist and futurist Roy Charles Amara’s “Amara’s Law” says, “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.”
In the short term, despite practical challenges, I believe prioritizing the resolution of specific pain points within current insurance practices—including concerns related to trust, operational costs and transparency—could be the primary emphasis for blockchain insurance initiatives. This will require developing and integrating blockchain technology in collaboration with InsurTech companies and employing suitable management strategies. However, this endeavor won’t be straightforward, as blockchain typically isn’t a plug-and-play solution to upgrade existing IT systems. Nonetheless, it is my understanding that many insurance firms maintain faith in the potential of blockchain technology, particularly in areas like smart contracts within parametric insurance.
In the long term, drawing insights from advancements in other financial sectors, I believe blockchain technology has the potential to integrate deeply into the insurance value chain. It may evolve into a resource, platform and ecosystem for constructing novel business models and seizing new business opportunities. Insurers could begin to perceive blockchain as a fresh ecosystem that facilitates the creation, distribution and administration of insurance products that cover both purely blockchain-based risks and traditional off-chain risks. Ultimately, it could formalize existing informal risk-sharing mechanisms that the underinsured and uninsured currently use, thereby reducing the insurance protection gap and promoting financial inclusion.
Strategic Options for Insurers
For More Information
- The SOA Research Institute’s report on blockchain: Blockchain Opportunities for Insurance and Financial Industries
- Crypto’s Role in Insurance from The Actuary
For me, predicting the development trajectory of blockchain insurance is challenging, particularly as current participants are predominantly technology firms operating within the insurance domain. For incumbent insurance companies, it appears to me that adopting a “no-regret” strategy entails cautiously investing in the blockchain insurance ecosystem. The initial step could involve identifying specific pain points within existing business practices that blockchain technology potentially could alleviate. I believe coordinating regulatory, business and technological aspects will be crucial for the successful implementation of blockchain insurance initiatives.
For established international re/insurance firms, initiating a pilot project in a new line of business or market could be a suitable strategy. Collaborations between re/insurance incumbents and blockchain technology companies can help alleviate issues related to insufficient digital literacy. I believe it is essential to have talent proficient in both the insurance industry and blockchain technology. Last but not least, developing an innovative technical and business model could be vital to addressing the challenge of integrating legacy IT systems.
Statements of fact and opinions expressed herein are those of the individual authors and are not necessarily those of the Society of Actuaries or the respective authors’ employers.
References:
- 1. Cherian, Joseph, and Yogi Thambiah. Are Cryptos an Investable Asset Class? Asia Asset Management, February 2022. ↩
- 2. Adel, Imane. How Blockchain Is Transforming the Entire Financial Services Industry. Forbes, June 2023. ↩
- 3. Goodenough Oliver, and Susan Salkind. 2022. Computable Contracts and Insurance: An Introduction. ↩
- 4. Jia, Ruo (Alex). Assessing the Potential of Decentralised Finance and Blockchain Technology in Insurance. The Geneva Association, August 2023. ↩
- 5. Ibid. ↩
- 6. Minnock, Olivia. A Closer Look at ZhongAn, One of Our Top 10 InsurTechs.” FinTech, May 2020. ↩